
n-gram은 주어진 문장에서 n개의 연속적인 단어 시퀀스(단어 나열)를 의미합니다.
n-gram은 문장에서 n개의 단어를 토큰으로 사용하며 이웃한 단어의 출현 횟수를 통계적으로 표현해 텍스트의 유사도를 계산하는 방법입니다.
if n == 1: return “유니그램 (Unigram)”
elif n == 2: return “바이그램 (Bigram)”
elif n == 3: return “트라이그램 (trigram)”
else: return “해당n 그램”
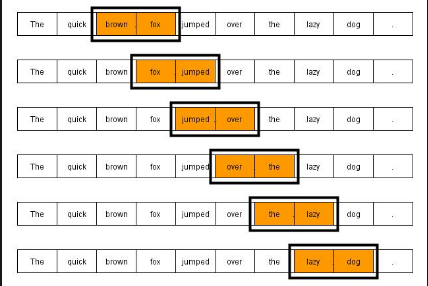
해당 문자을 n-gram으로 토큰을 분리한 후 단어 문서 행렬(Term-Document Matrix, TDM)을 만들고 두 문장을 서로 비교해 동일 한 단어의 출현 빈도를 확률로 계산해 유사도를 구할 수 있습니다.